
Geen categorie /
Intelligent Document Technology: IDT
Intelligente verwerking van binnenkomende informatie
Ondanks de toenemende digitalisering neemt de hoeveelheid informatie die organisaties jaarlijks moeten verwerken gestaag toe. Hoewel dit nog grotendeels papieren documenten zijn, bestaan er al sinds enige jaren digitale tegenhangers. Niet alleen het volume van de binnenkomende informatie neemt toe, maar ook de heterogeniteit. E-mails, formuliergegevens en vragen via websites zijn slechts enkele voorbeelden. Ook social media en messengerdiensten zoals WhatsApp worden in toenemende mate gebruikt door organisaties voor zakelijke doeleinden. Dit brengt nieuwe uitdagingen met zich mee voor de verwerking.
Om deze diepgaande vloed van documenten en gegevens het hoofd te bieden, is intelligente documenttechnologie nodig om alle binnenkomende informatie van een organisatie – op papier, gedigitaliseerd of volledig digitaal – op een holistische manier te bundelen, te automatiseren en te optimaliseren. Intelligent Document Technology zorgt voor kanaalonafhankelijk registratie, extractie en verwerking van relevante informatie door krachtig en toekomstgericht inputmanagement.
Wat is inputmanagement?
In essentie verwijst inputmanagement naar het capturing van relevante gegevens binnen documenten met behulp van capture software technologieën. Het omvat registratie, automatisering en verwerking van de informatie in inkomende documenten. Gegevens worden via OCR (optical character recognition) herkend, geïnterpreteerd en geëxtraheerd, zodat de essentiële informatie zo snel mogelijk de juiste plek binnen in de organisatie bereikt. Dit kunnen digitale documenten of papieren documenten zijn. Om papiergebaseerde documenten te kunnen verwerken, moeten deze eerst worden gescand en dus gedigitaliseerd.
Inputmanagement is een integraal onderdeel van onze Intelligent Document Technology en wordt gebruikt in een breed scala aan scenario’s van alledaags werk, zoals digitale factuurverwerking.
Geautomatiseerde documentverwerking
Bij inputmanagement worden documenten voor het eerst geïdentificeerd als een specifiek documenttype (bijvoorbeeld een factuur). Dit gebeurt op basis van specifieke kenmerken van de respectievelijke documenten. Een inkomende factuur wordt bijvoorbeeld geïdentificeerd op basis van een betalingsreferentie, een bijzonder kenmerk van dit documenttype. Op basis van de identificatie vindt een bepaald type verwerking plaats. Dit kan bijvoorbeeld zijn het doorsturen van het document naar een specifieke persoon of afdeling (bijvoorbeeld voor ondertekening) of het automatisch extraheren en doorsturen van de documentgegevens naar een ander systeem zoals DMS, CRM, ERP of een financieel pakket.

Registratie, automatisering en verwerking van binnenkomende informatie: de fases
Het verwerkingsproces met Intelligent Document Technology kan in verschillende stappen worden verdeeld. Dit zijn:
- Intake & Import
- Documentoptimalisatie
- Classificatie
- Herkenning & extractie
- Validatie
- Verificatie
- Export
Deze stappen bouwen gedeeltelijk op elkaar op. Maar vanwege de modulaire structuur zijn niet alle componenten onderling afhankelijk.
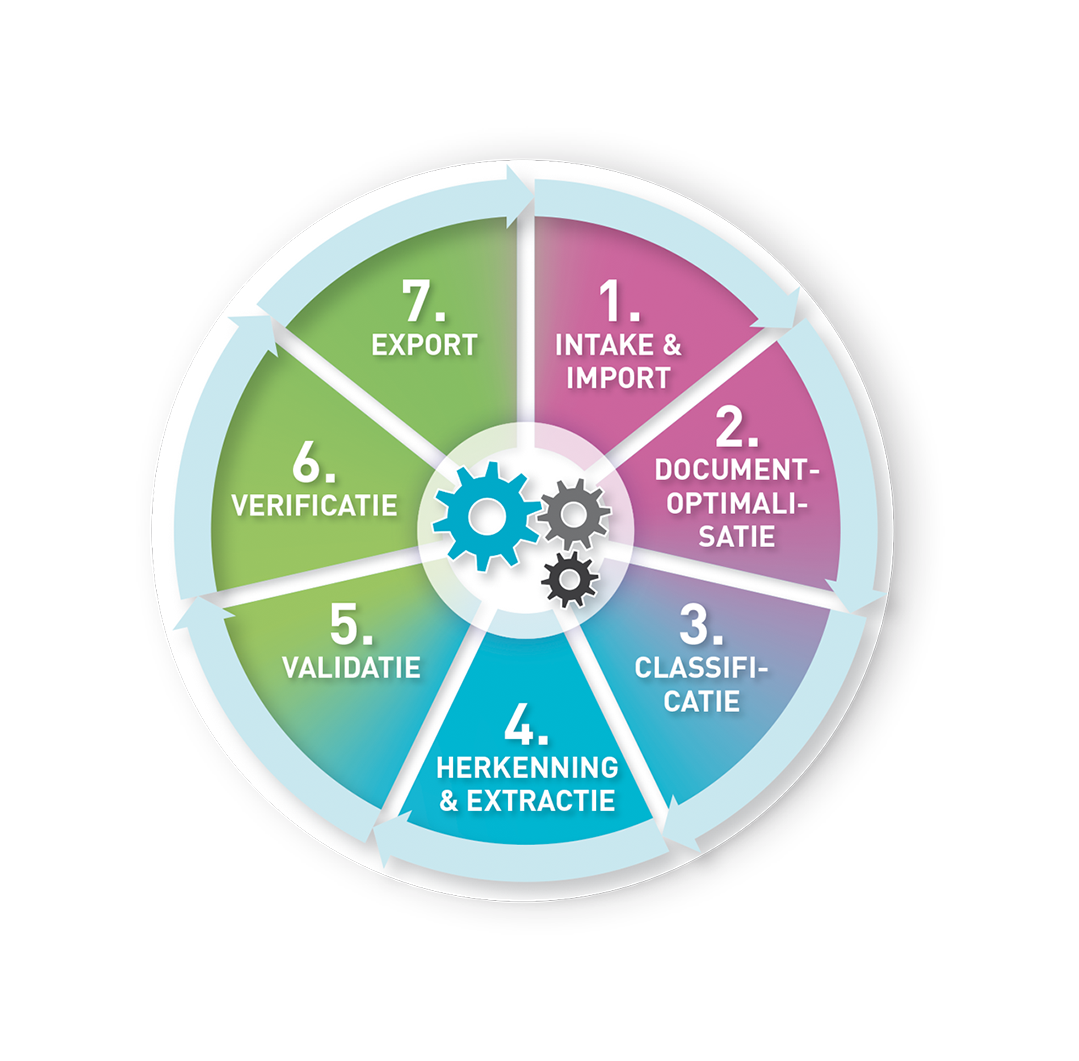
Mogelijkheden van Intelligent Document Technology
1. Intake & Import
Papieren documenten die nog niet digitaal zijn, worden gedigitaliseerd (= gescand) en kunnen full text worden doorzocht met behulp van OCR. Digitaal geboren (dus elektronisch gegenereerde) documenten worden geïmporteerd. Het ingangskanaal doet er in wezen niet toe.
2. Preprocessing
Voor foutloze document capture kunnen gescande papieren documenten worden geoptimaliseerd. De software zet bijvoorbeeld gescande documenten recht of verwijdert knikken en vlekken. Documenten met meerdere pagina’s of verschillende soorten documenten kunnen in deze stap worden ingedeeld als ze dienovereenkomstig zijn gemarkeerd, bijvoorbeeld met streepjescodes of met scheidingspagina’s.
3. Classification
Gescande documenten worden toegewezen afhankelijk van hun vorm en inhoud. Deze zogenaamde classificatie kan vrij worden bepaald via flexibel definieerbare attributen. De classificatie van een document bijvoorbeeld als een factuur of als een bestelling is gebaseerd op woordherkenning of vergelijkingen met bekende documenttypen. Op basis van deze voorbeelddocumenten kan de software worden getraind. Ze “leert” dienovereenkomstig met elke herkenning, welk documenttype het is. Op deze manier kunnen facturen, bestellingen, formulieren en andere documenten automatisch worden geclassificeerd.
4. Recognition & Extraction
Naderhand vindt de software de benodigde gegevens in de documenten en haalt ze eruit voor verdere verwerking. Individuele bestanddelen en hun positie in het document worden zodoende herkend (dit wordt ook wel documentherkenning of alleen herkenning genoemd) en uit het document gehaald (de technische term hiervoor is extractie of data-extractie) om ze door te sturen naar een specifiek systeem en/of een bepaald proces. Bij facturen worden bijvoorbeeld typische elementen zoals factuurnummers, leveranciersgegevens of bedragen herkend en geëxtraheerd.
5. Validation
Vooraf gedefinieerde regels controleren de herkende inhoud op volledigheid en juistheid, bijvoorbeeld of een IBAN correct is gespeld en de beoogde lengte heeft. Validatie vermindert de menselijke fouten aanzienlijk en vermijdt verwerkings- en overdrachtsfouten. Desgewenst bevat deze fase ook functionaliteit voor documentvergelijking – een krachtig hulpmiddel om snel verschillende versies van documenten te vergelijken en verschillen in één oogopslag zichtbaar te maken.
6. Verification
Als er een afwijking is, wordt deze onmiddellijk aan de gebruiker getoond en kan deze worden gecontroleerd en gecorrigeerd. Deze handmatige verificatie is maar geen must.
7. Export
In de laatste stap worden de vastgelegde documenten automatisch opgeslagen als een volledig doorzoekbaar PDF-, PDF/A- of TIF-bestand. De geëxtraheerde inhoud wordt als een XML- of CSV-bestand opgeslagen of geëxporteerd naar relevante verwerkingssystemen, zoals een DMS-, ECM-, of ERP-systeem of een financieel pakket. De technologie is dus een nuttige aanvulling op complementaire systemen om documenten met toegevoegde waarde te digitaliseren en de metadata rechtstreeks te verwerken.