
BCT Essentials Plattform
Die Plattform mit essenziellen Softwareprodukten für schnelle, digitale und durchgängige Dokumentenprozesse
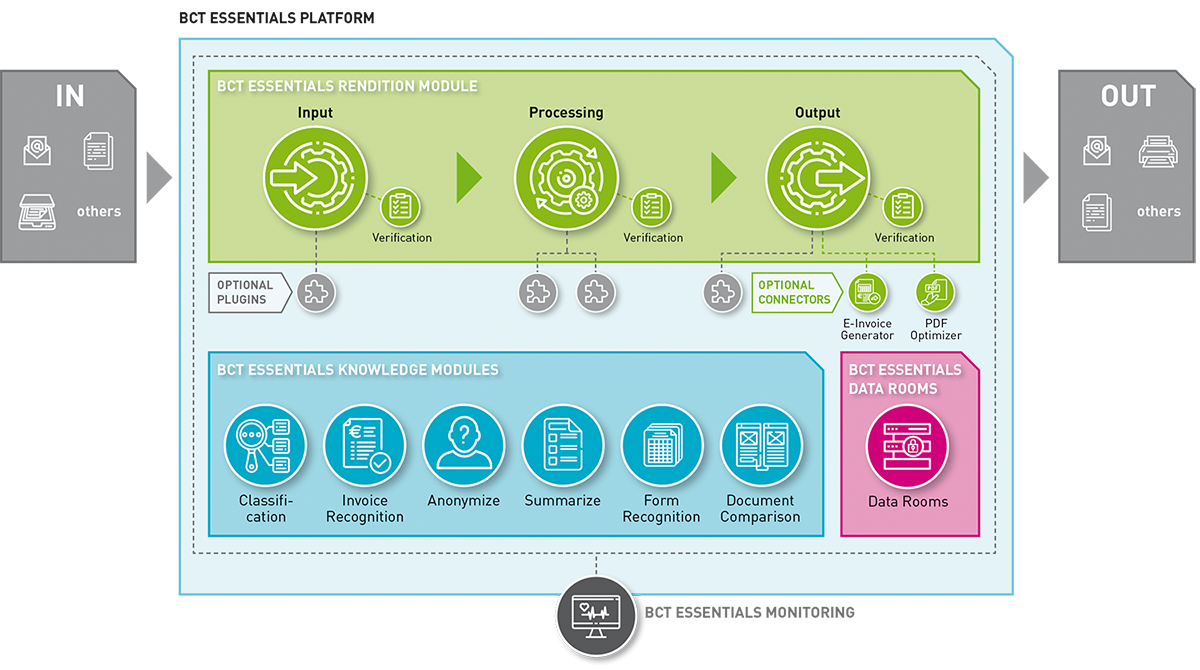
Die BCT Essentials Plattform ist die technische Grundlage für eine kontextbezogene Umwandlung, Verarbeitung und Aufbewahrung relevanter Informationen, indem sie ein- sowie ausgehende Informationsströme bündelt, digitalisiert, transformiert, automatisiert und optimiert. Die Plattform ist offen, modular, komplementär, skalierbar und kontextspezifisch anpassbar. Basierend auf jahrelanger Erfahrung von BCT im Bereich der Compliance-konformen Dokumentenerfassung, -verarbeitung und -aufbewahrung, bietet sie nahezu unbegrenzte Möglichkeiten – unabhängig von Art, Umfang oder Übermittlungskanal der Dokumente. Mit dieser Plattform und den darauf basierenden essenziellen Softwareprodukten bietet wir unseren Channelpartnern das ultimative Rüstzeug für schnelle, digitale und durchgängige Dokumentenprozesse.
Mehr Infos zu unserer Plattform?


BCT Essentials Rendition

BCT Essentials Wissensmodule
BCT Essentials Datenräume
BCT Essentials Connectors
BCT Essentials Monitoring